Part
01
of one
Part
01
Demand Side of Data Labeling
Key Takeaways
- The types of services provided by the data annotation industry include image classification, object detection/segmentation, image segmentation, and image boundary recognition for Computer Vision (CV) applications.
- Healthcare innovation providers and social media companies, such as Facebook, are among the many types of companies that require data labeling services to build their products and services.
- One case study of a company using third party data labeling services is Google in its collaboration with Snorkel to develop the Snorkel DryBell project used in building Google classifiers.
Introduction
This research identifies the types of services provided by the data annotation industry, the population/companies that require such services, and a case study of an organization that uses data labeling services.
Insight #1: Data Labeling/Annotation Industry Services
- Data labeling is one of the most critical factors to the success of any application that requires high precision ML (Machine Learning) models and systems. Cognilytica, an AI research and advisory firm, found that data engineering and preparation tasks take as much as “80% of the time consumed in most AI and Machine Learning projects.”
- CV systems are built to exercise optical perception and intelligence, like humans. One way of doing this, supervised learning, works by teaching a computer to perceive, interpret and understand optical information by teaching it with samples (data sets) that are already labeled. This is similar to teaching a child with pictures.
- Simple image annotation is applicable in image classification. In this use case, an image may be labeled with some text describing features such as the name, type or color of an object. A good example of this is how retail shops tag products on the shelf.
- More complex image annotations reveal more details about an image. Such details may include frequency, size or similar tasks that require better judgment and discretion to be successful.
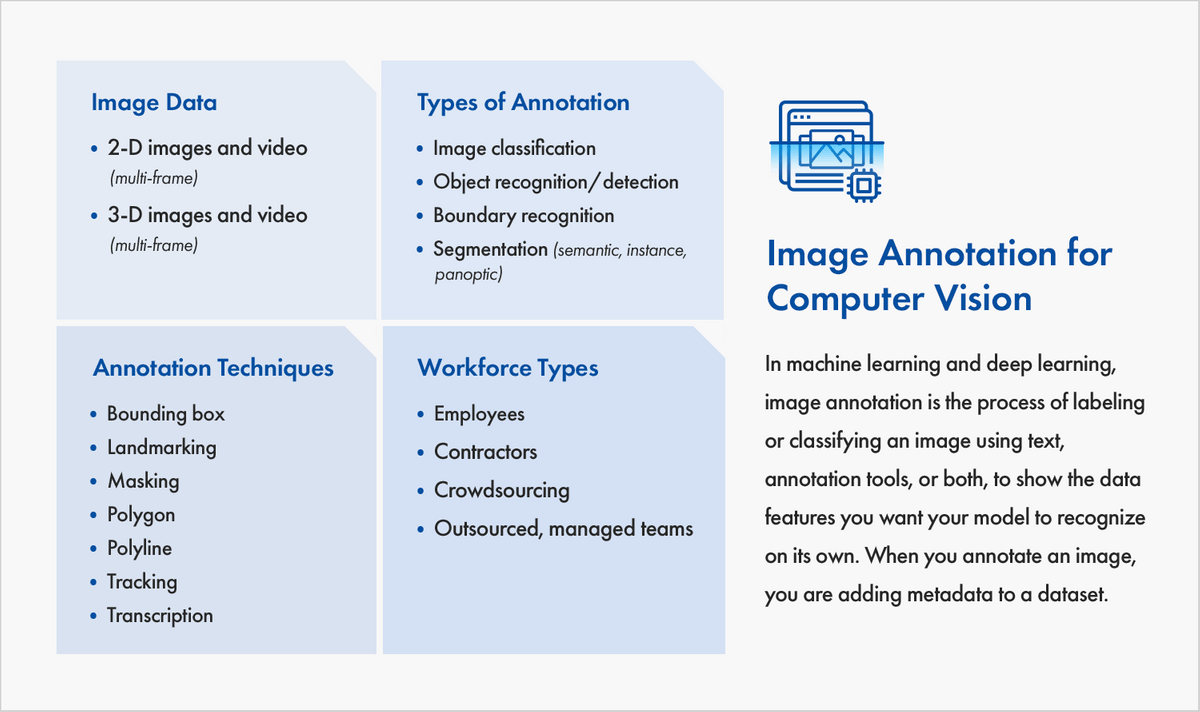
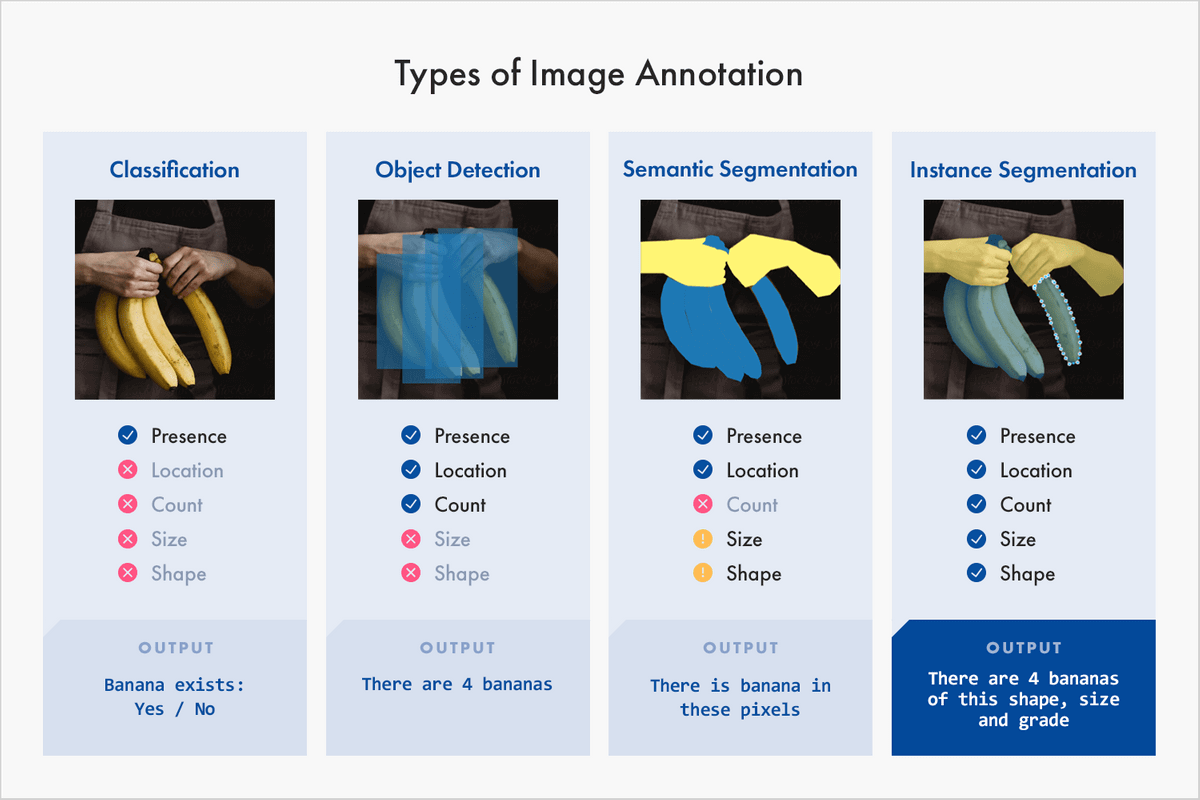
- Generally, there are four types of image annotation services provided in the data labeling industry: image classification, object detection/segmentation, image segmentation, and image boundary recognition.
- Image classification aims to “identify the presence of similar objects depicted in images across an entire dataset.” Image classification applies to all parts of an image at a broad level.
- Object recognition/detection aims to “identify the presence, location, and number” of objects in an image to label them correctly.
- Image segmentation applies at a more advanced level to study the contexts and changes in the details of an image.
- Like segmentation, boundary recognition applies to the details of an image, but its boundaries. It helps a computer system to identify applicable areas of an image based on boundaries and zones. This is particularly useful in autonomous vehicles, among other applications.
- Speech, in whatever language, requires annotation for computers to learn, understand, and manipulate it. Language annotation is crucial to applications such as virtual assistants, chatbots, language translators, and search engines.
- The most general types of text annotation/labeling include:
- Entity annotation
- Entity linking
- Text classification
- Sentiment annotation
- Linguistic annotation
Service #1: Image Labeling/Classification for computer vision systems
Service #2: Language Learning and Annotation for Natural Language Processing
Insight #2: Companies Requiring Data Labeling/Annotation
Healthcare and Medical innovation companies
- Surgery, patient engagement and health records are all areas that apply data labeling/annotation to create solutions for both patients and healthcare practitioners. The medical application of AI is a sensitive and delicate field, hence high accuracy is important in building solutions for the field. High-accuracy labeled data are the foundations of ensuring the accuracy of the final solution.
- For example, the diagnosis of medical conditions may involve the analysis of medical scans. Human error in such applications can be deadly. AI systems are trained to help analyze medical scans by teaching them from already annotated images that are consistent with a diagnosed condition.
- Similarly, in surgery, systems are built to increase the efficiency of surgeons and make surgeries safer. To achieve this, medical experts work with specialized annotations professionals to identify and label critical structures in surgical videos. One such project involved “pixel-level annotation of the various anatomic structures within a Robotic Coronary Artery Bypass Graft or CABG video.”
Social Media companies: Facebook's Halo
- Facebook built Halo (Human-AI loop), a framework to create and set up pipelines for annotation and training data, to enable researchers to build higher performance ML models.
- Although the goal of the project was to enable Facebook researchers to focus on building ML models and not on building annotation tools, it serves to show the importance of quality annotated data in the social media space.
- One standout example of how Facebook researchers use Halo, hence data annotation, is in the Rosetta tool. Rosetta “detects and recognizes text in visual media, including images and video.” The team of Facebook researchers annotated hundreds of thousands of images from a dozen languages. The team of researchers used the annotated data to train a model that “served as a signal in a meta-classifier that proactively protects people from harmful content, such as posts that contain hate speech.”
Insight #3: Data Labeling/Annotation Case Studies
Google With Snorkel DryBell
- Google is an AI giant as most of its services and products integrate the technology in many ways. One important tool in the inner workings of Google’s application of AI in its products and services is a classifier. These classifiers commonly find application in content and product recommendations, social media analytics and so on. However, there was a problem.
- According to Snorkel, a company that specializes in building and training ML data, “Google spent months and considerable resources manually labeling and relabeling thousands of data points for each classifier.”
- To solve this problem, Snorkel, in collaboration with Google, built Snorkel DryBell, a project involving the development of two kinds of classifiers — topic and product classifiers. The goal of the project was to achieve “the accuracy attained by hand-labeling in a fraction of the time.”
- With Snorkel DryBell, Google labeled 684,000 data points for use in a topic classification model, only in a few minutes. More of the project results are below.

Research Strategy
To answer this request, the research team consulted publications from enterprise practitioners in the data labeling space, such as CloudFactory and Snorkel, as well as pioneers of use cases that pioneer technologies and offerings that depend on data labeling, such as Meta(Facebook) AI. These sources provided sufficient information to identify the types of services provided by the data annotation industry, the population/companies that require such services, and a case study of an organization that uses data labeling services.