Part
01
of one
Part
01
AI Training
Key Takeaways
- The global AI Training market size value was estimated at US $1.15 billion in 2020 and US$1.4 billion in 2021.
- Market values for the data annotation tools market varies among producers of market reports. One market report estimated the market to be valued at over US $1 billion in 2021 with another expecting this to increase to US$1.3 billion in 2022.
- The market size for the global data collection and labeling market is projected to be US$8.22 billion by 2028, with a CAGR of 25.6% over the period 2021 to 2028. In 2021 the market was sized at US$2.6 billion.
- Key components for successful AI Training include the availability of high quality data, accurate data annotation, and an experimentation culture.
- Factors to be considered when choosing a data annotation platform are data quality, dataset management, annotation efficiency, use cases, interconnectivity, specialized features, ability to automate, support availability, price, and security.
Introduction
- In the brief below market data, inclusive of market size value, revenue forecast and compound annual growth rates, are provided for the AI Training and Data Annotation and Labeling markets, along with overviews of the AI Training and Data Annotation and Labeling industries.
Markets
AI Training Market
- The global AI Training market size value was estimated at US $1.15 billion in 2020 and US$1.4 billion in 2021.
- The compound annual growth (CAGR) is forecasted at a rate of 19.5% between 2021 and 2028, with the estimated market size at US$ 3.1 billion in 2027, and US $4.90 billion 2028.
- Additional market data.
- A major market driver is an increased supply of synthetic training data to be used in the supervised and unsupervised training of algorithms for machine learning. Adoption of AI fueled by changes to the operational model during the COVID-19 pandemic and increased dependency on automation and other advanced technologies are fueling deployments in industries such as ecommerce, healthcare, and IT and automotive.
- Growth factors for the industry are enhancements to AI training datasets and the need to ensure the increasing volume of unstructured data is trained for machine learning.
- Market restraints are related to the lack of an expert workforce, surges in demand for image or video AI training as opposed to the other types, and the outlook for the end-users. CAGR for the image/video segment is forecasted at 22% over 2021 to 2028.
- High adoption rates are driving growth in the Asia-Pacific region, while in Europe market CAGR over the period 2021 to 2028 is forecasted at 20.6%. Market share in 2020 was led by North America with 38.7%
- Text accounted for 32.9% of the AI training dataset market share, but by vertical IT accounted for 31.5%
Data Annotation Tools Market
- Market values for the data annotation tools market varies among producers of market reports. One market report estimated the market to be valued at over US $1 billion in 2021 with another expecting this to increase to US$1.3 billion in 2022.
- CAGR is forecasted at one market report to be over 30% during the period 2022 to 2028 while another report forecasts a CAGR of 15.1% over the forecast period of 2022 to 2032, and third projects a CAGR of 27.1% between 2021 and 2028.
- One report estimates the market value in 2028 at US $10 billion, while another forecasts a significantly lower figure of $US 3.4 billion in 2028. Finally, a forecast of US $5.3 billion is projected for 2032.
- Growth drivers include increasing demand for annotated data to be used in improving machine learning models, more investments in autonomous driving technologies, and increased adoption of data annotation in medical imaging and document classification.
- Regionally, South Asia and Oceania is expected to grow at a CAGR of 18% during the forecast period, however North America retains market dominance with a 32% global market share. Manual annotation is the type with the largest market share of 76%, however automatic annotation tools are expected to grow at a CAGR of 17%.
Data Labeling Market
- The market size for the global data collection and labeling market is projected to be US$8.22 billion by 2028, with a CAGR of 25.6% over the period 2021 to 2028. In 2021 the market was sized at US$2.6 billion.
- Alternatively, the global data labeling solution and services market is projected to be worth $38.11 billion by 2028 with a CAGR of 23.5% over the period 2021 to 2028.
The AI Training Industry: An Overview
Overview
- The AI Training process comprises three stages: training, validation, and testing. Training is the initial step and refers to the stage when the AI is just beginning to learn what is required. Validation is the next stage and this is where assumptions about the performance of the AI using the new set of data is validated. Testing is the stag where the AI's performance is subjected to real-world conditions.
- Key components for successful AI Training include the availability of high quality data, accurate data annotation, and an experimentation culture.
- The AI Training market is segmented by application into image/video, text, and audio segments, and by end users into the IT & telecom industries, retail and e-commerce, government, healthcare, automotive, and others.
- By geography the market is segmented into North America (US, Canada, Mexico and rest of North America), Europe (Germany, UK France, Russia, Spain, Italy, and the rest of Europe), Asia-Pacific (China, Japan, India, South Korea, Singapore, Malaysia, and the rest of Asia-Pacific) and LAMEA (Brazil, Argentina, UAE, Saudi Arabia, South Africa, Nigeria and the rest of LAMEA).
Regulatory Oversight
- Regulatory concerns regarding AI that are directly impactful to AI Training are primarily associated with the handling of data and the outcomes from its deployment. Privacy, biased algorithms, and misinformation speaks to how data is sourced and used, the potential for discriminatory results due to statistical model or data bias, and development of deepfakes. Additional concerns are the potential for harmful acts committed or resulting from AI deployments, and the threat of hacking.
- An overview of the AI, Machine Learning, and Big Data laws and regulation in 2021 can be accessed at this link. Free online access is provided for six chapters discussing the issue from an overall perspective, as well as jurisdiction chapters for 24 countries with substantial deployments of AI.
- The regulatory framework for the United States is listed below.
- National AI Strategy — The National AI Initiative Act of 202 established the National AI Initiative Office charged with the development and oversight of a national AI strategy for the US. The Office will also act as a central hub for the private and public sector, as well as academia in AI research and policy development.
- National AI Strategy — Section 1260 of the Innovation and Competition Act, which makes $80 billion available for AI, robotics and biotechnology.
- National Security measures include algorithmic governance, publications of the National Security Commission on Artificial Intelligence (NSCI) Report, the release of the Department of Defense Innovation Unit Responsible AI guidelines, and the Artificial Intelligence Capabilities and Transparency (AICT) Act.
- Additional measures undertaken in the US related to facial recognition and biometric technologies, algorithmic accountability, and state and city regulations can be accessed at this link.
- A sample of regulatory Developments in the European Union are listed below.
- The European Commission released a draft AI Regulation on 21 April 2021.
- A AI Draft Report on AI in a Digial Age was released by the EU Special Committee in November 2021.
- A joint opinion was published by the European Data Protection Board and the European Data Protection Supervisor calling for a ban on the use of AI for facial recognition in publicly accessible spaces.
- Policy and Regulatory Developments in the UK include the launch of a National AI Strategy, the publication of an Ethics, Transparency, and Accountability Framework for Automated Decision Making, a Standard for Algorithmic Transparency, the publication of a Commissioner's Opinion on the use of live facial recognition, and the publication of a Consultation on the Future Regulation of Medical Devices in the United Kingdom.
Typical Services Offered
- Data Services offered include the provision of training data for speech, natural learning processing, computer vision, quality assurance, and for translation. Typical products are in data sourcing (pre-labeled datasets and data collection), data preparation (data annotation, platform tools, and knowledge graph and ontology support),
- Speech training data may take the form of monologue, dialogue, and spontaneous speech. Natural language processing services include workflows for collection (text variant, conversation, and surveys), entity tagging and annotation (named-entity tagging, semantic annotation, and sentiment tagging), and computer vision (text validation and test correction).
- In terms of computer vision, workflows can be accessed for collection and annotation (image and video collection, 2D and 3D cuboid annotation, polygon lines and bounding boxes, semantic and instance segmentation, and synthetic data generation) and object identification, classification, tracking, and recognition (object detection, tracking, and identification, image classification, landmark annotation, key point tracking, object and environment mapping with LiDAR, and optical character recognition).
- AI Training is also available for quality assurance with experience workflows available for validation and evaluation (mean opinion score testing, MUSHRA Testing, ABX testing, and pronunciation validation), evaluation of experience service in action, and evaluation of experience metrics.
- Translation datasets provide services in translation workflows (human and machine translation, paraphrasing, and translation validation), hybrid workflows (annotation and translation, and gender disambiguation), machine translation quality evaluation (side-by-side comparison, acceptability testing, and in-context quality evaluation), and multilingual dataset translation quality.
Pricing Model
- A bare-bones machine learning model was estimated in 2021 to cost approximately $60,000 over a period of five years, while the cost for a scaleable framework is approximately $95,000.
- Components of the pricing model are the infrastructure on which the model will be deployed, data support, engineering, and deployment.
- The costs for additional deployments are outlined below.
- Customers that opt for the provision of cloud-based machine learning services can adopt a pay-as-you-go pricing model with one year or three year reserved virtual machine instances as with Microsoft Azure. Pricing at Azure is also available under Dev/Test pricing rules under an Azure subscription.
- At AWS, pricing for machine learning services are available under free trials, but also on a price per unit for the various services. Here is the pricing breakdown for Amazon Comprehend.


Operational Model
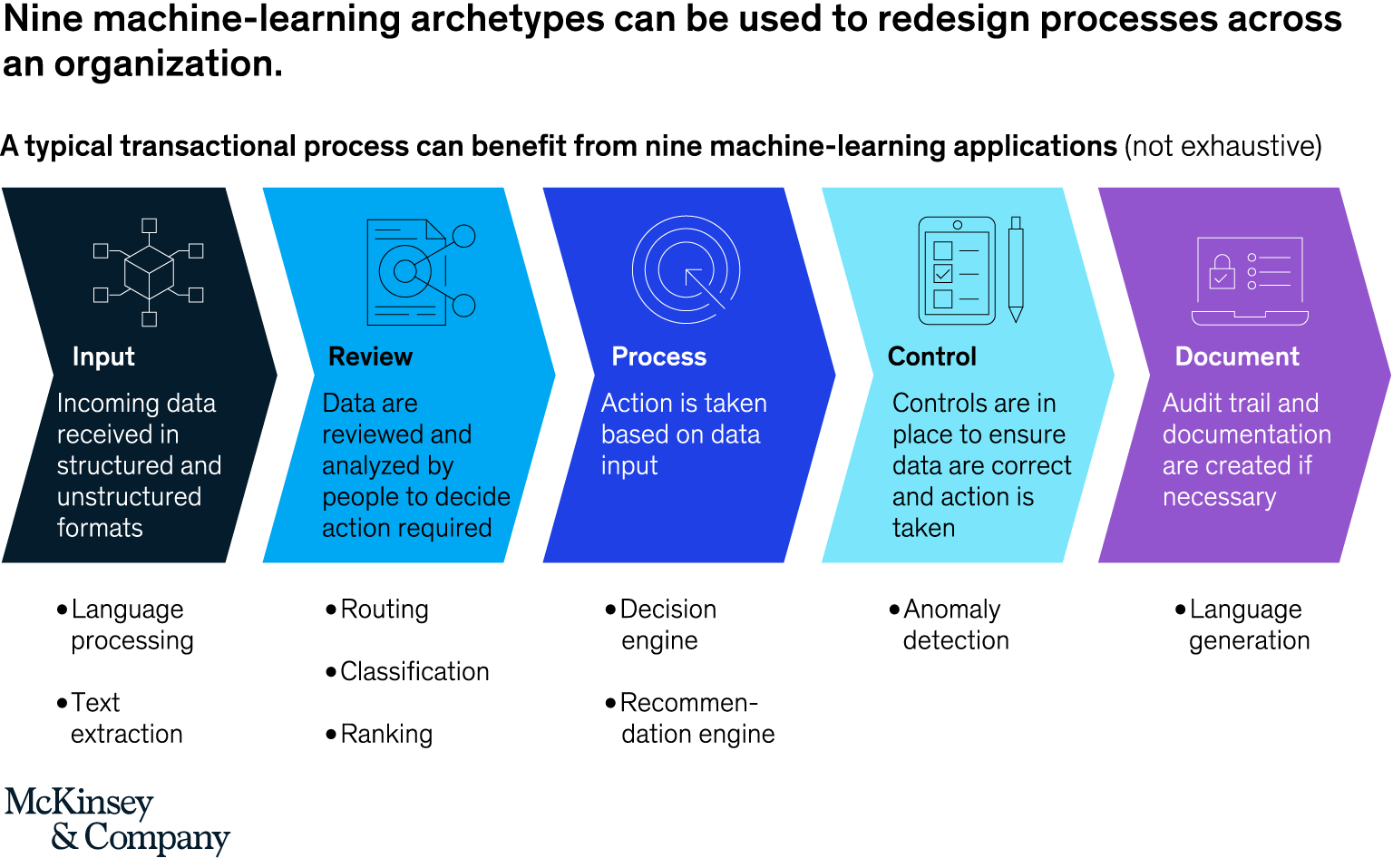
- According to McKinsey, machine learning processes built into processes by organizations increase process efficiency by 30% and resulted in increased revenues by 5% to 10%. A healthcare company that deployed a predictive model saw a reduction in manual effort by 25%.
- Organizations are advised to first consider economies of scale and skill when operationalizing. These addresses challenges associated with siloed efforts such as model integration and data governance. Processes that are designed to be automated from end-to-end allows for synergies in the types of inputs, controls, documentation, processing, and review protocols.
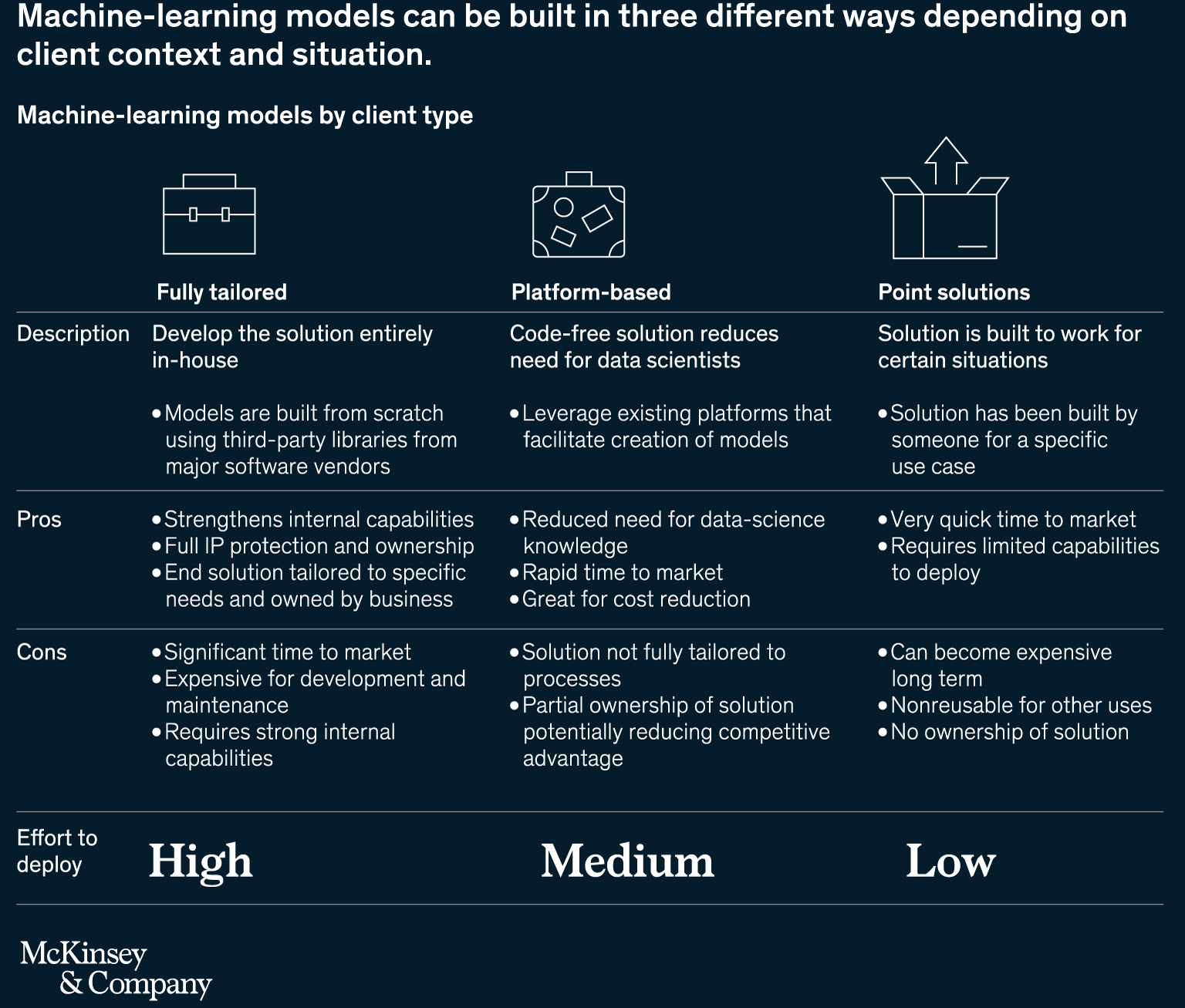
- Next, capability needs and development methods should be assessed. Options for building the machine learning models include building fully tailored models, using a solutions, and purchase point solutions.
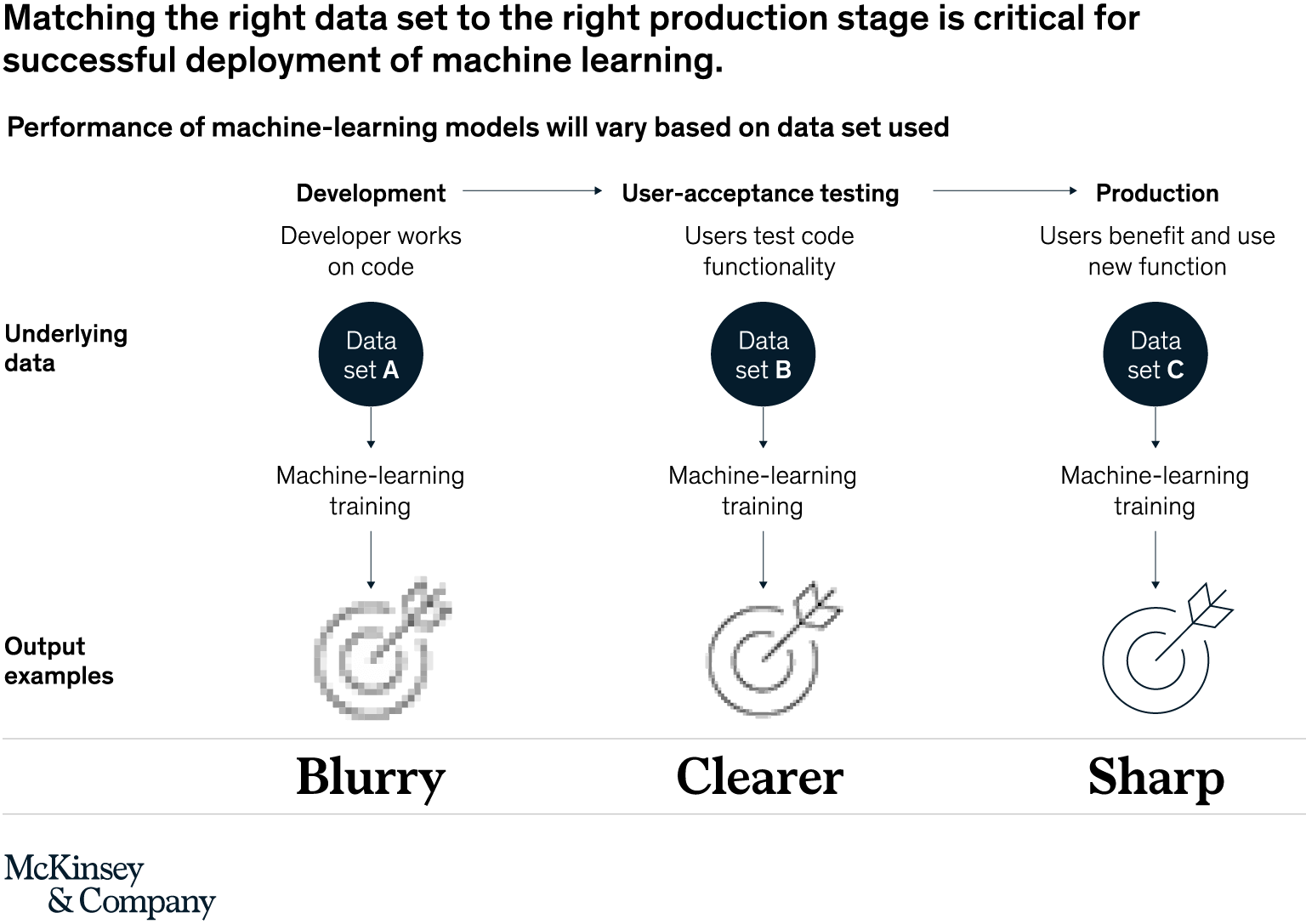
- The third step recommended by McKinsey is to have the model trained on-the-job preferably with respect to data management and quality.
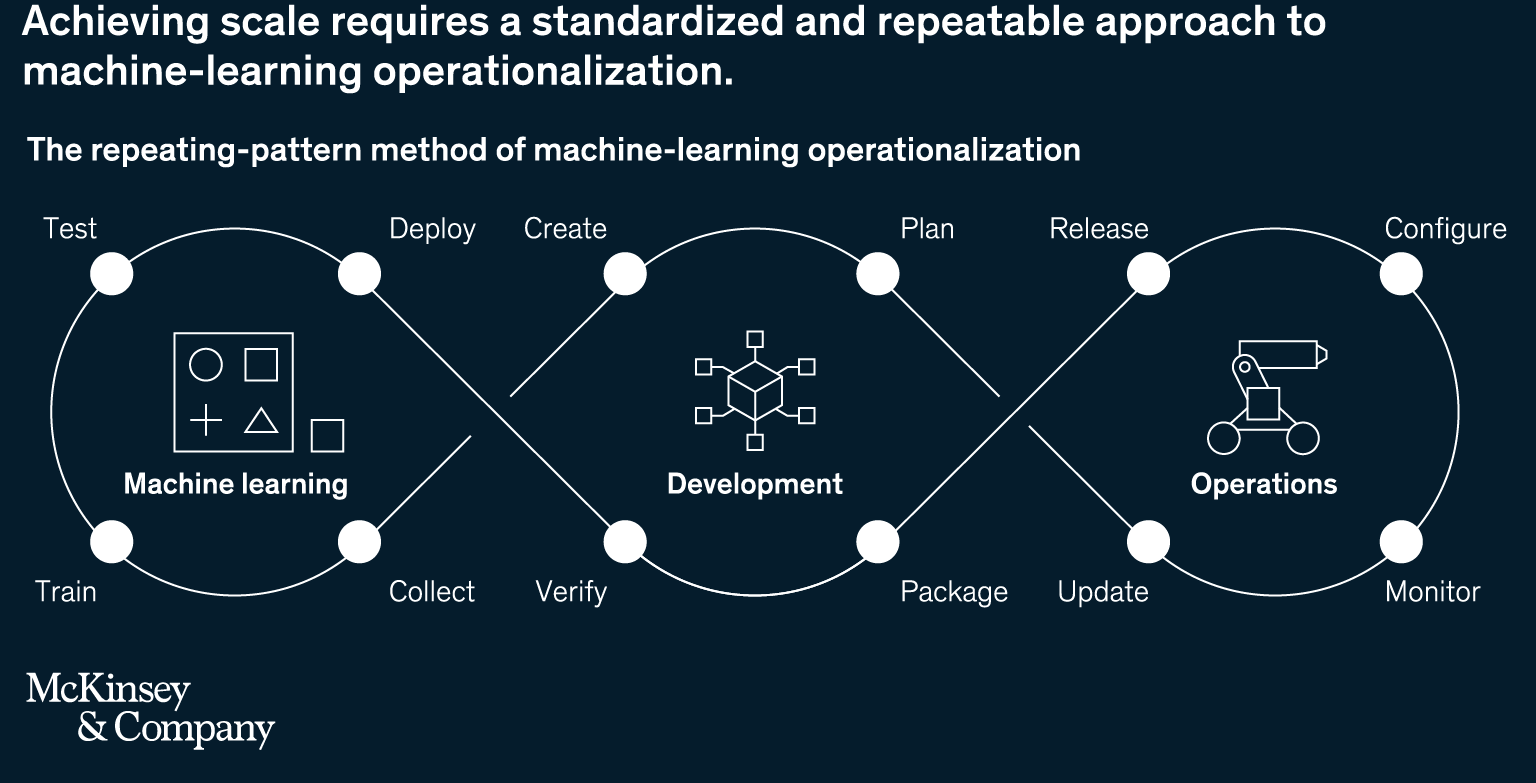
- The fourth step is to standardize the machine learning project for deployment and scalability. MLOps, DevOps applied to software development and IT operations is one example of the best practice that can be used as a guide. MLOps seeks to reduce the life cycle for analytics development and whilst increasing the stability of the model from the automation of repeatable steps in the workflows of software practitioners (such as data scientists and engineers). The image below illustrates the repeating-pattern method.
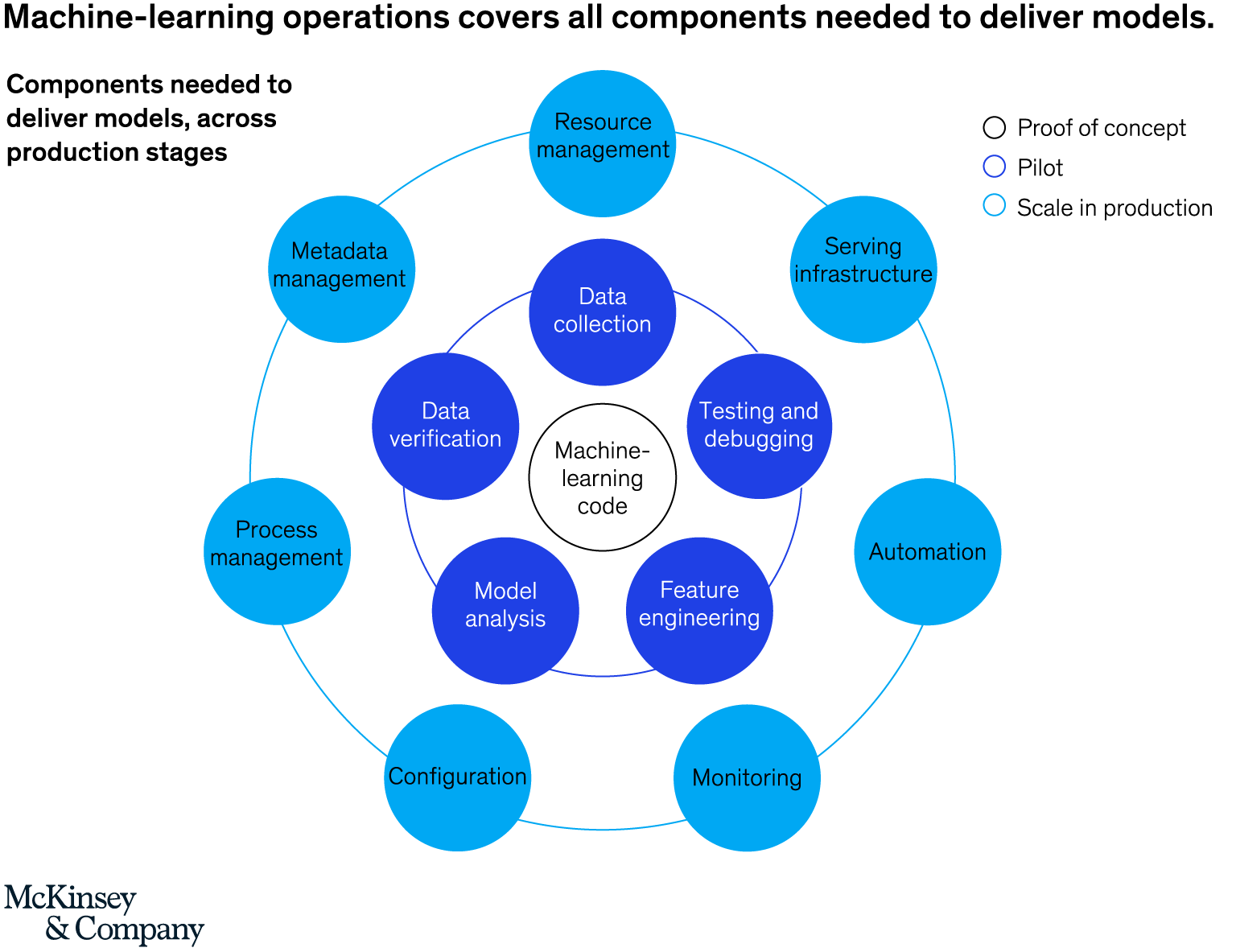
- The next image illustrates the components required to deliver models.
- Key phases of MLOps are data analysis, data gathering data transformation/preparation, model development, model training, model validation, model serving, model monitoring, and model re-training. Along with best practices for machine learning model management, and a comprehensive review of four ways to implement machine learning model management, this article provides valuable information regarding operationalizing machine learning.
Additional Useful Information
- Additional Useful Information: Recent Partnerships, Collaborations, and Agreements
- Amazon partnered with Hugging Face in March 2021, a firm working on natural language processing technologies to increase adoption of models for natural language processing.
- Scale.ai partnered with MIT Media Lab in June 2021 to assist the healthcare industry with offering better care for patients through the use of machine learning.
- TELUS partnered with Google in February 2021 to provide deployment services for the Cloud Contact Center AI solution at Google.
- Appen partnered with the World Economic Forum in August 2020 to create standards for responsible AI.
- Microsoft partnered with SAS in July 2020 to form a long-term strategic partnership in analytics, artificial intelligence, and cloud.
- Additional Useful Information: Mergers and Acquisitions
- Appen acquired Quadrant in August 2021. This enhances Appen's offering in mobile-location based data collection.
- TELUS Corporation acquired Lionbridge AI to supports its ability to assist technology brands with next-gen AI and data annotation.
- Microsoft acquired Nuance Communications, a company operating in speech recognition and AI, to provide better solutions for healthcare and to offer customer experiences in every industry that is more personalized.
- TELUS acquired Playment in July 2021, an acquisition that enhances TELUS's expertise in data annotation.
- Additional Useful Information: Product Launches and Expansions
- Google Cloud launched the managed machine learning platform Vertex AI in May 2021.
- Cogito expanded annotated data capabilities in health care.
- Appen launched new off-the-shelf datasets for human-body movement, baby crying sounds, and scripted speech and images.
- In 2021, AWS announced several key updates for Amazon SageMaker.
- Scale.ai launched Pandaset, an advanced LiDAR commercial dataset in May 2020.
The Data Annotation and Data Labeling Industry: An Overview
- Factors to be considered when choosing a data annotation platform are data quality, dataset management, annotation efficiency, use cases, interconnectivity, specialized features, ability to automate, support availability, price, and security.
- Data labeling can be done manually or automatically. The image below illustrates manual data labeling.

Regulatory Oversight
- Regulatory Oversight for data annotation and data labeling is very similar to that of AI Training. Specific to data management, legal instrument have been enacted in the EU General Data Protection Regulation (GDPR) regulations, the Personal Information Protection Law (PIPL) in China, and the UK GDPR.
- No overarching legislative instrument specific to data labeling or annotation was sourced for the US, however the FTC has begun using section 5 of the FTC Act, the US Fair Credit Reporting Act and the Equal Credit Opportunity Act to regulate the industry currently.
- The approaches to the regulation of Big Data that are currently being taken is regulation from multiple standpoints such as with the Data Strategy from the European Union and a practical approach where existing rules are adapted to the current reality.
Services
- Services typically provided by data annotation and labeling providers include data annotation, computer vision, natural language processing, data processing, workforce management platform, workforce strategy, data security and partnerships.
- Services can also be provided for classification services, transcription services, entity annotation and linking, and sentiment analysis.
- Items to be considered when choosing a service provider include security of data, technology and tools, and data types.
Pricing Model
- Price considerations for data labeling are project duration, quality, turn around time, and cost, the pricing model, and internal costs.
- Factors to be considered when choosing a data annotation platform are data quality, dataset management, annotation efficiency, use cases, interconnectivity, specialized features, ability to automate, support availability, price, and security.
- Pricing can be done by the hour or per task and incentives can be made from labeling data with higher quality or greater volume.
- Data science developer Hivemind undertook a study comparing the quality and cost of data labeling completed by a managed workforce and one completed by the anonymous workers on a crowdsourcing platform. In the study the two teams were given tasks in easy transcription, sentiment analysis, and to extract information from unstructured text.
- For the transcription, the crowd sourced workers had an error rate 10 x higher than that of the managed workforce. For sentiment analysis, the managed workers again performed better than that of the crowd sourced workers, and for extracting information from the unstructured text managed workers accurate was 25% higher than that of the crowd sourced team.
- Critical considerations for data labeling pricing are the existence of a predictable cost structure, pricing that fits for purpose, and the flexibility to make changes as data characteristics change.
Operational Model
- Strategies organizations can employ to ensure that the labeling operation is optimal is to begin by figuring out the business case specifics, beginning with a small project and proceeding by iteration, proper documentation and assessment of the process, and investments in expertise.
- Data Labeling has five main components: tools, quality, workforce, pricing, and security. Choosing data labeling tools is important in terms of annotation tools, how easily they can be integrated, and how easily the tools can be used by annotators. Data labeling automation occurs from level 0 where there is no automation, level 1, where there is some tool assistance, level 2 where there is partly automated labeling, and level 3 highly automated labeling.
- Quality assurance is considered the most critical part of data labeling and is measured from test questions, heuristic checks, and sample quality check. In terms of the Workforce model it is important to determine when it is time to scale and hire a data labeling service.
- Model approaches include internal operations where the in-house teams build out the dataset e.g. Tesla, crowdsourcing where freelancers complete the process using programs such as Amazon Mechanical Turk, and outsourcing, where an outside team is hired to provide data labeling service.
- Automatic data labeling refers to model assisted labeling, AI assisted labeling, auto labeling and custom auto labeling. Model-assisted labeling refers to the labeling of what is usually a small dataset initially and in the training of an AI system sorely for the purpose of labeling. Benefits and limitations of this method can be accessed at this link. The image below illustrates the process for model-assisted labeling.
- AI-Assisted labeling is where companies use an AI-assisted annotation system. The benefits and limitations of this approach can be accessed at this link, while the image below provides a graphical representation of its processes.
- A graphic outlining the process for auto-labeling is presented below.




Research Strategy
For this research on AI Training, we leveraged the most reputable sources of information that were available in the public domain, including from the websites of industry practitioners such as AWS, TELUS Corporation, Appen, and Scale.ai.